In our previous blog post, we talked about serverless architectures and different interpretations of the term. On one end of the spectrum, we had Amazon RDS (Relational Database Service) and on the other AWS Lambda.
Amazon EMR is also serverless in the sense of Amazon RDS: software installation and system maintenance are of no concern, while the concept of a server machine remains a basic building block. We will also come around to an earlier post on scalability and how horizontal scaling benefits both cost and performance.
Recently we were working on a project that required flexible horizontally scalable data processing. While we were considering the usual frameworks like Apache Spark, newcomer Flink caught our eye. After due deliberation, we decided to go with Flink as its feature-set seemed to not only meet our requirements, but also meshes well with our usual technology stack.
Flink is a streaming dataflow engine developed by the Apache Foundation.
Flink is a streaming dataflow engine developed by the Apache Foundation. At a glance, it’s very similar to the more well-known Apache Spark, and their API’s are quite similar. The fundamental difference between the two is that while Spark is a batch-processing engine with support for realtime streams through the processing of small batches of data, Flink was built from the ground up as a native streaming dataflow engine, where data is immediately pushed through the pipeline as soon as it arrives. Batch processing is also supported and built on top of the streaming framework. This makes Flink’s architecture a sort of middle ground between Spark’s ease of use and Storm’s high performance stream processing capabilities.
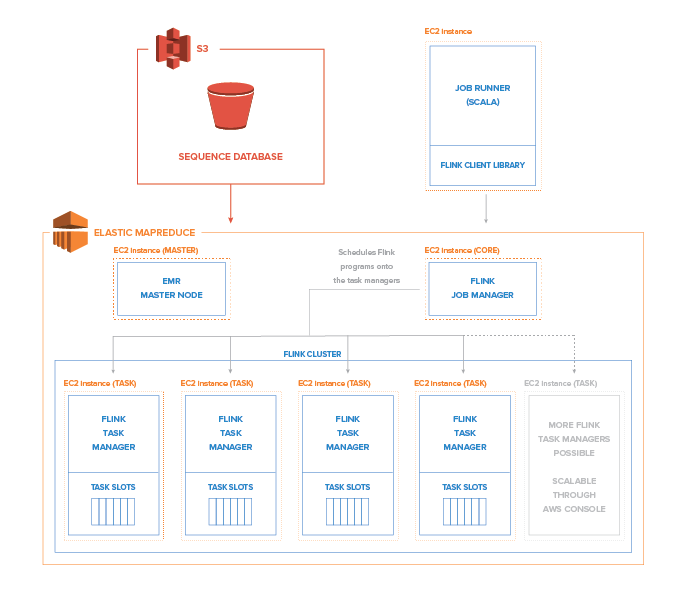
At XAOP, we have used Flink to develop a highly distributed pipeline for the calculation of pairwise protein sequence alignments. We chose Flink because it is an interesting new technology, which has recently been gaining traction. Its first fully stable version 1.0 was released earlier this year (March 2016). It provided a fitting solution to our problem and integrates seamlessly with most Amazon Web Services. Since Flink can run on a Hadoop YARN cluster, it’s also possible to run it on Amazon EMR, allowing us to minimize the deployment effort and fully virtualize our processing resources. This approach also significantly reduces EC2 (Elastic Compute Cloud) costs, since most of the calculations can be offloaded to much cheaper EC2 spot instances.
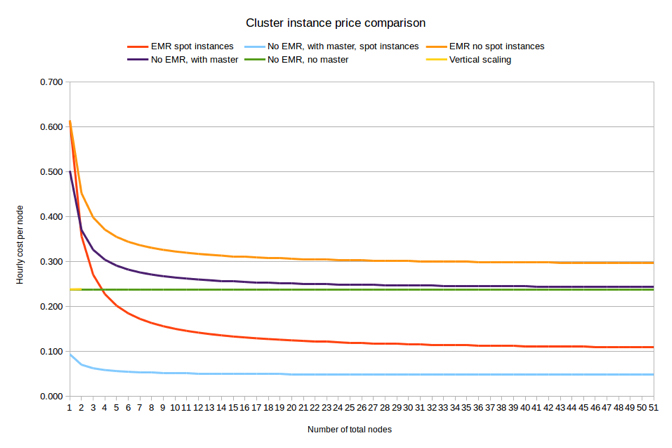
In one of our earlier posts, we mentioned that the cost difference between vertical and horizontal scaling for on-demand instances is negligible. However, the same principle does not hold when using spot instances. While bare EC2 spot instances induce a considerable maintenance effort, using spot instances with Amazon EMR is exceedingly simple. For our EMR cluster, we need a master and a core instance to meet the minimum cluster requirements, but after that we can easily scale horizontally using very cheap spot instances straight from the AWS console (we don’t need HDFS persistence for our calculations). Unfortunately, as of the writing of this post, this does require a restart of the Flink cluster as well. For us this is currently not a deal-breaker because the spot market price for the instances we are using does not fluctuate heavily. However, if you want to make proper use of the flexibility of EC2 spot instances, this is definitely a missing feature. YARN hosted autoscaling is listed on Flink’s roadmap for 2016, so we do expect this problem to be addressed by the Flink development team relatively soon.
While bare EC2 spot instances induce a considerable maintenance effort, using spot instances with Amazon EMR is exceedingly simple.
All in all, our first experiments with Flink have been a positive experience. It was relatively easy to integrate in our application, using Amazon S3 hosted datasets was painless and the option to deploy on Amazon EMR reduces the time normally spent configuring a Hadoop cluster. We are certainly looking forward to using it again in future projects.